
December 17, 2024 ⏱️ 6 min
By Andreea S. & Tibi V. (RnD – WebFrontend Group)
In today’s digital era, the ability to communicate with devices and application through voice commands reshaped the way users are interacting with technology, making them more natural than ever.
From experienced virtual assistants like Siri, Google Assistant or Alexa, the way users interact within web applications by using hands-free and voice-controlled features, instead of traditional input methods, it’s no longer a dream, but it’s becoming a necessity.
Overview
Imagine if, instead of navigating, the user will just say “show me the last order entries”. Although it can sound like your web application has its own genie’s lamp, voice-driven experiences are closer than ever, though they can sometimes tread the line of overengineering.
In this this article we will walk you through how to add voice capabilities to your web application, allow it to respond with actions, using modern Speech Recognition APIs.
What is Speech Recognition
In simple words, Speech Recognition is the capability of a program to listen and interpret user’s voice commands and respond appropriately, instead of typing it, allowing more accessible and efficient ways of interactions. This technology is widely (and most commonly) used in virtual assistants, transcription services or voice-controlled applications, offering a natural and intuitive way to interact with the system.
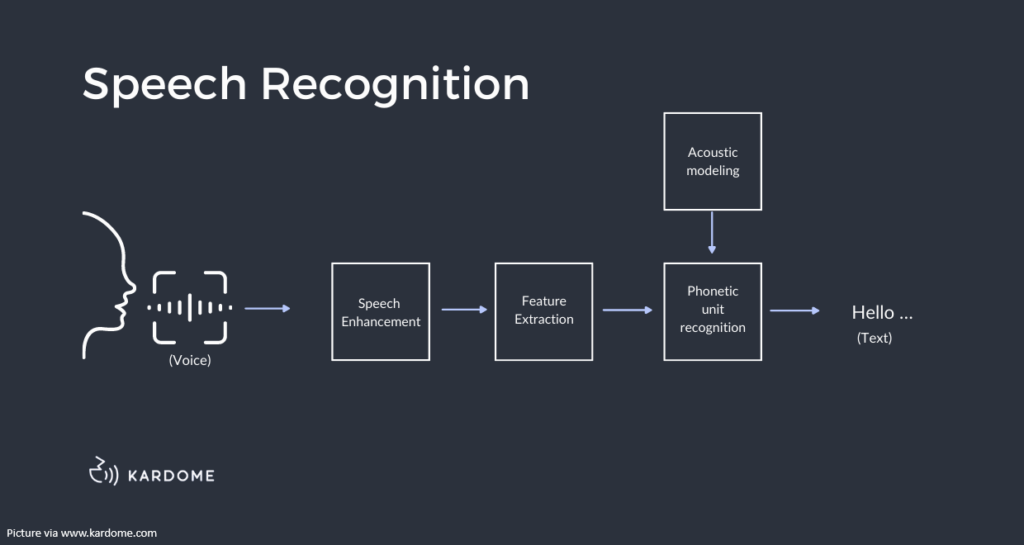
The technology behind voice recognition has been available for quite some time, but only reached its peak usage recently, due to several key factors:
- Smartphones can be considered as the catalyst of this evolution, as the increased usage of mobile devices has also increased the user demand for quicker and more natural ways to interact with technology.
- Also, recent technological advancements have allowed speech recognition accuracy to reach rates of over 95%, making voice a viable alternative to text.
Web Speech API
One of the most widely used JavaScript API, known for its powerful capabilities to incorporate voice-driven and speech-synthesis features into web applications is Web Speech API.
This API empowers web developers with the tools necessary to incorporate both speech recognition and text-to-speech functionalities, without any necessity of installing extra drivers and/or plugins. So, when the user starts recording a command like “search for customer Allen Brown”, this API starts transcribing the spoken input into text and further, your system will trigger specific actions.
It introduces two key components:
-
- Speech recognition (also known as speech-to-text). This feature converts the user’s spoken input (voice) into text. It can be implemented by using the SpeechRecognition interface, enabling the system to process and respond to voice commands.

- Speech synthesis (also known as text-to-speech – TTS) – This feature transforms written text into spoken words. It can be implemented by using the SpeechSynthesis interface.
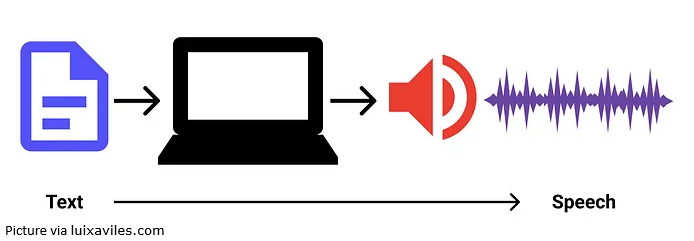
- Speech recognition (also known as speech-to-text). This feature converts the user’s spoken input (voice) into text. It can be implemented by using the SpeechRecognition interface, enabling the system to process and respond to voice commands.
Speech Recognition Use Cases
If you wonder where speech recognition technology finds its space in the business world, here are some use cases where it revolutionizes the way businesses interact with technology:
- Interactive search & navigation – Although it’s a standard feature in the majority of smartphones and devices, the ability to speak queries instead of typing them, offers significant advantages. It proves especially beneficial in scenarios where handling tasks simultaneously is mandatory, or when a quick hands-free solution is needed for the users to interact within the application.
- Dictation & transcription – One of the most popular use cases is dictation. For example, an application with speech recognition features can be used to convert voice-recorded patient reports into written text documents. This process not only saves times for healthcare employees but will improve the accuracy of their Electronic Health Record (HER) system record.
- Sentiment analysis – Speech recognition is not only about transcription, but with the help of some NLP algorithms it can also determine a score for the conversation, such as positive, negative, or neutral. Based on the response, the system can adapt its response further.
- Voice detection for animal sounds – apart from human voice, the speech recognition technology can be extended to recognize and analyze animal sounds too. This capability can help in monitoring the presence and behavior of wildlife in particular areas, migration patterns, endangered species, etc.
- Voice authentication – Like a fingerprint or retina scan, as an extra layer for security, making use of the unique biometric characteristics of someone’s voice, you can identify certain users and allow them access to the system. This process helps in scenarios where, for example, only a specific category of users can access a private information, such as opening a medical record, opening a room, or initiate a financial transaction.
Web Speech API: How It Works
In simple words, it’s an interface that’s able to listen and interpret user’s voice commands and respond appropriately, instead of typing it, allowing more accessible and efficient ways of interactions.
But let’s dive deeper and understand how this process works. Here are the basic principles that facilitate this technology:
-
- Browser compatibility – The first step is to ensure the application works on a compatible browser. At the time of writing, the Web Speech API is still experimental with limited browser compatibility, with officially support on Chrome – see supported browsers for more information.
- Voice capture – Next, using SpeechRecognition interface, the system starts to capture the audio user input, by turning on the device’s microphone and responding accordingly. For example: When the user says “create invoice for customer Allen Brown” the system listens and records this voice command, and it starts to initiate the interpretation process.
- Speech Recognition analysis – Once the recording is complete, the recognition service algorithm starts to process the audio recording using speech features (like a list of grammar), returning a result (as a text string) and the onResult event triggered.
- System output – Once the result is successfully processed, by extracting certain words from it, the system can trigger specific actions on your application. For example: If the user says something containing “customer Allen Brown”, then the system can identify a form with a field “customer”, and automatically have it selected if the user is found in the system.
Web Speech API Challenges
It’s important to mention that, although the Web Speech API offers a solid ground by its two key features, it does have some limitations:
- While for simple and direct commands, it can work like a charm, for complex phrases it can transcript or format issues differently (for example: due to accent, background noise or poor audio quality).
- Browser support is limited
However, this is not an impediment, because a good alternative is to use cloud-based APIs, such as Speechly, Google’s Text-to-speech API or Microsoft’s Azure Cognitive Speech Services. These APIs provide pre-build speech services, with simple API calls, which can be used as a bridge between the user’s voice input and your web application.
Voice Commands in Web Applications
Voice-command features can enhance user experience, and here are the most important reasons why to do it:
- Improved accessibility – Voice command features will enhance the accessibility of web applications for all types of users, and it will allow them to easily navigate and interact with main features.
- Time saving and efficiency – Voice commands can reduce time, making interactions more efficient, by offering a hands-free way of working, especially when it comes to searching, giving commands, and completing forms. For example, users can search for customers, invoices, read details and even start a task within even having to touch the keyboard, touchscreens or even mouse.
- Innovation – By integrating voice commands it results in innovative applications, staying in trends and meet user expectations for modern, interactive web experiences.
Conclusion
In conclusion, the integration between JavaScript and modern Speech Recognition APIs marks a significant step forward in technology innovation. And if you think that voice driven interaction is not ready to ‘be a thing’ yet, keep in mind that in 2018, 27% of the global online population was using voice search on mobile devices while more recent surveys show that in the United States, 41% of adults were using voice search daily as of 2023.
Therefore, whether it’s to boost productivity, streamline communication, or keep up to date with the latest industry trends, embracing the potential of voice-driven experiences is no longer optional, but it’s becoming a necessity. Creating and designing conversions between spoken language and written text and shifting towards voice-enabled technologies will enhance engagement and offer users more intuitive, dynamic, and accessible web experiences.
Îndemnul nostru
Efortul pus în programele pentru studenți completează teoria din facultate cu practica care “ne omoară”. Profitați de ocazie, participând la cât mai multe evenimente!
În cei 3 ani am lucrat la proiecte diverse ce au contribuit decisiv la evoluția mea profesională. Am colaborat strâns cu echipe remarcabile, a căror dedicare și sprijin au fost fundamentale în buna dezvoltare a lucrurilor. Cu fiecare proiect, am învățat nu doar aspecte tehnice, ci și abilități esențiale de comunicare și colaborare, reflectate în experiența mea privind interacțiunile cu clienți și modul în care o echipă eficientă operează. Aceasta este cultura companiei, de la ritmul uneori alert al zilei de lucru și practicile Agile, până la momentele relaxante de socializare cu colegii în pauzele de cafea și activități recreative precum darts și ping pong.

Am făcut cunoștință cu echipa NetRom prin intermediul programelor Internship și NetRom Software Academy, in care am descoperit că noțiunile învățate acasă au totuși aplicabilitate, chiar în cadrul unor aplicații reale. Acele experentie m-au convins să aplic pentru un job.
Mentorii foarte deschiși și colegii cu experiență care mi-au răspuns prompt la toate neclaritățile au transformat provocările în task-uri rezolvate cu succes împreună. Făcând parte din #teamnetrom mi-am depășit frica de a greși și am evoluat într-un mod echilibrat pentru mine.

Am aflat de programele NetRom de la o prezentare organizată în facultate de companie. Am decis să mă înscriu la Summer Camp din dorința de a înțelege ce anume ar presupune o cariera în IT. În urma acestui stagiu de practică, am reușit să dezvolt propria aplicație cu ajutorul mentorilor care mi-au oferit informații teoretice, dar mai ales practice, pe care nu aș fi putut sa le găsesc într-un tutorial aleatoriu de pe internet. Modul meu de abordare a aplicaților s-a schimbat odată ce am înțeles în ce constă mai exact procesul, ce presupune un mediu real de lucru și importanța muncii în echipă.

NetRom Software Testing Academy a fost punctul de plecare pentru o carieră pentru mine. Pe parcursul sesiunilor am avut oportunitatea să cunosc bazele necesare pentru asigurarea calității unui produs, urmate de o zi în companie unde am văzut teoria pusă în practică.
Recomand tuturor celor care își doresc o carieră în QA să ia în considerare această academie, fiind destinată atât celor din domeniu, dar nu numai.

Am descoperit NetRom prin intermediul unui program de internship și am fost impresionată încă de la început de mediul de lucru plăcut, de susținerea și angajamentul colegilor. A fost o oportunitate deosebită de a lucra într-o echipă de proiect, cu roluri specifice, și de a înțelege mai bine cultura companiei. Întreaga perioadă s-a dovedit o experiență valoroasă, atât din punct de vedere al cunoștințelor acumulate, cât și prin prisma relațiilor dezvoltate. În momentul în care mi s-a propus să continui ca angajat permanent, a fost o decizie ușor de luat, bucuroasă fiind să pot aplica cele învățate, dar și să adaug cunoștințe noi în fiecare zi.
